

Introduction
In this article, we will learn about a probabilistic data structure called Bloom Filters. Burton Bloom introduced it in 1970 and defined it as something that will return whether an element is "possibly present" or "definitely not present".
Let us first see the problem statement with an example,
Suppose, you are building an application where every user while registering needs to enter a username for their profile which has to be unique. Now to make sure that the username is unique we have to check if the entered username is present in our database or not and then either let the user know or let them register their profile.
The easiest way to do it will be to hop over every element in our database and see if it is equivalent to the passed in username. Sounds simple right? Yes, but there is a caveat.
This approach however will take O(n) which is good for a small sample size but not if we have millions of data in our database. Another problem will be while scaling our servers as it will be very difficult to maintain the list of usernames across distributed servers.
This is where Bloom Filters comes in.
What is Bloom Filter?
Bloom Filter is a space-efficient probabilistic data structure. It is used to answer the question - Is the element present in the set? and it would answer with either a “firm no”, or a “probably yes”. This means that false positives are possible while false negatives are not possible. In simple words, if the element is not there the bloom filter might say it is but if the element is there the bloom filter would never say it is not.
If this sounds confusing, no worries. We will discuss it more elaboratively with an example down the lane. So keep reading!!
The “probably yes” part is the reason why bloom filters are known as probabilistic data structures. So here we are trading a bit of accuracy to save a lot of memory.
Now let's see the working principle of a Bloom Filter
How does Bloom Filter work?
Bloom Filters are usually used for problems where we have to find some properties of a string or for quick and efficient string comparisons.
For cases where string comparison is needed, we don't want to store the entire string. Rather we would store the hashes of the string to make efficient comparisons as the hash of something will just be a number so it will be a single comparison.
But a problem with hashmaps is that they might not have the bucket range to store all the strings. One way to work around it would be to store multiple hashes.
So in our example, we will be considering 3 hash functions and a binary array initialized by 0. If we pass a string through these 3 hash functions we will get three numbers and set the value of the binary array whose indexes are equivalent to the hashed outputs to 1. Now we take the string we want to identify and pass it through the same hash functions which will again give us 3 outputs. If the indexes in the binary array equivalent to the outputs hold a value of 1 then it means the element MIGHT exist, if any of them are 0 then the element certainly does not exist.
This might exist outcome is called a false positive and hence bloom filters are probabilistic.
Sound too complex? Let us break it down with an example...
Example of Bloom Filter
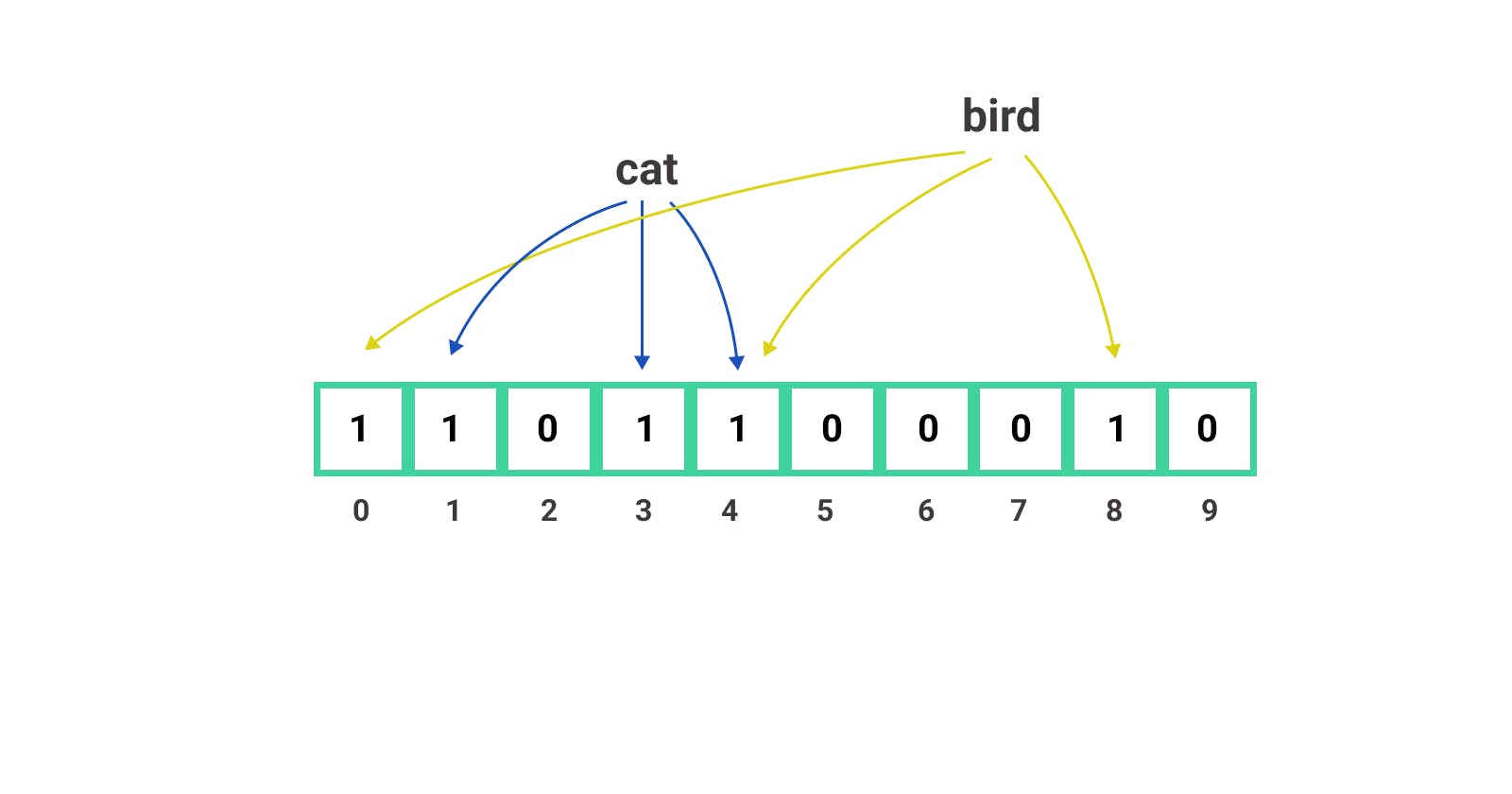
Let us take 3 hash functions f(x), f(y), f(z), and a bloom filter of bucket size 10 with 0 set in it. Now we will start by putting the string cat into the filter by passing it into the hash functions and getting 1, 3, and 4 as outputs. These numbers would be the indexes where the bucket value will be set to 1. This will take constant time.
Next, we will again put bird in the filter. The hash functions, in this case, let's say return 0, 4, and 8.
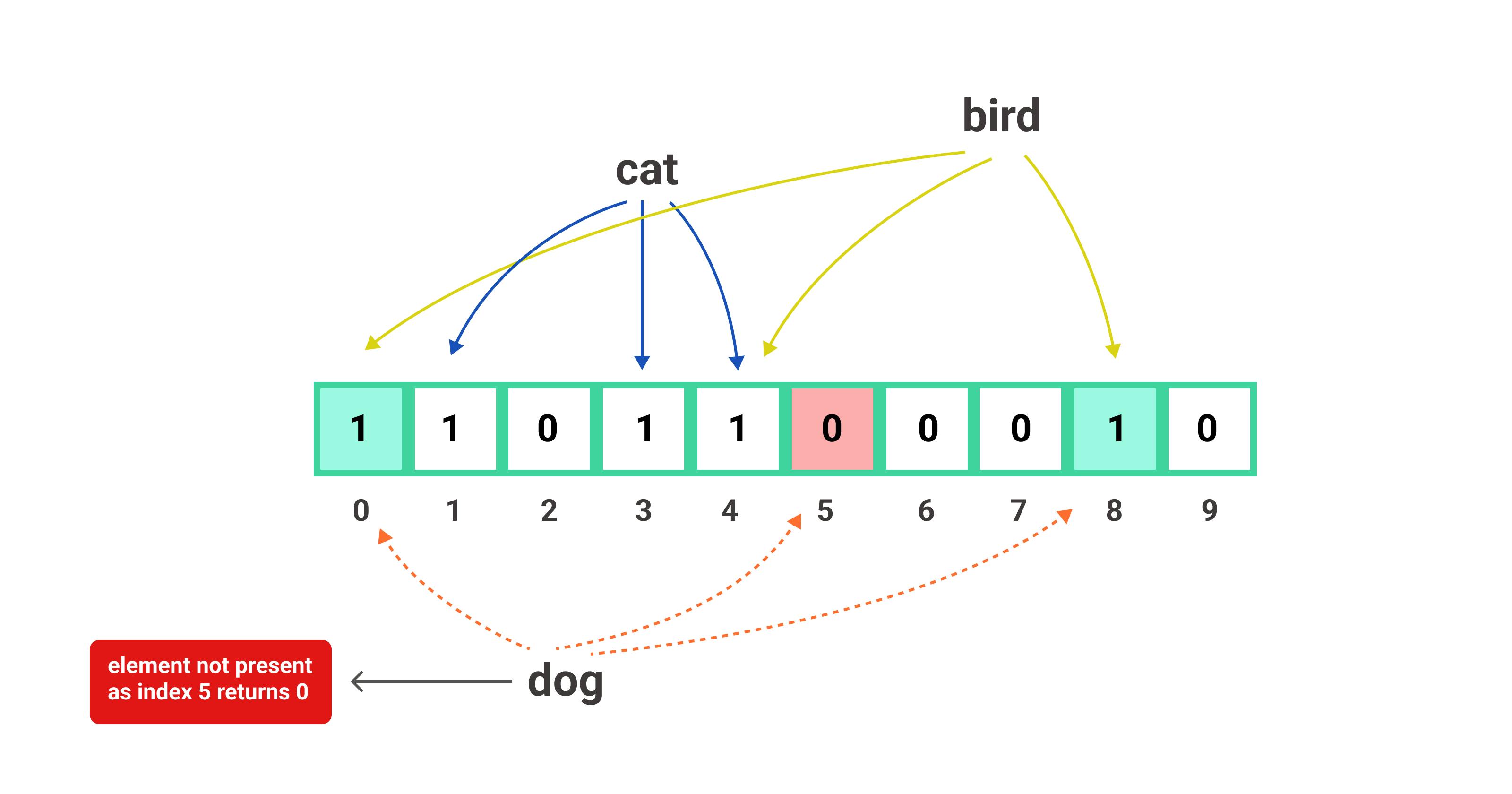
Now, if a search query comes with the string dog and wants to check if the query string has been searched previously or if it is present in our database then we will first check the bloom filter to avoid unnecessary lookups in our database. Let us see how we will do that.
We will first pass the query string that is dog through the same 3 hash functions and suppose they return 0, 5, and 8. In this case, we can see even though 0 and 8 locations in the filter have the value of 1 but 5 is still 0. So the bloom filter can confidently say that dog has not been searched or is not present in our database.
Now coming to the case of false positives, suppose we passed bat as the query string and it hashes to buckets 3, 4, and 8. Now when checked against the bloom filter we can see that all the buckets are set to 1 and hence, the bloom filter will eventually return a positive value that the element is present in our database which it is not.
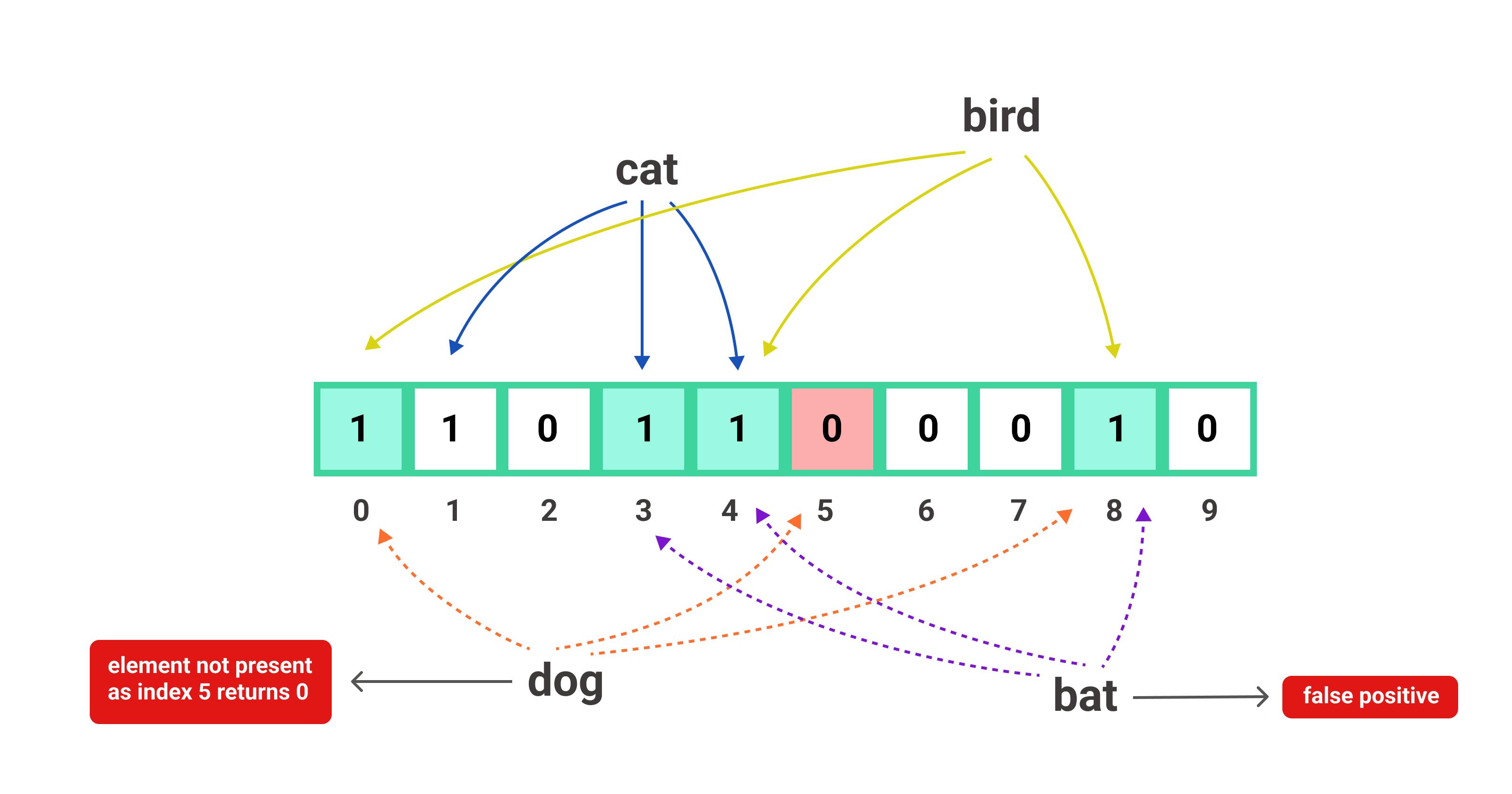
Thus, the bloom filter always answers with either a “firm no”, or a “probably yes” and this is what makes it probabilistic.
Things to keep in mind
One of the most critical elements of a good bloom filter is the hash function. These hash functions should be fast, and they should produce outputs that are evenly and randomly distributed.
Collisions can happen, but it is okay as long as they are rare because they increase the probability of false positives.
In real-life applications, the size of the bloom filter is much larger than considered in the above example. We can control how often we see false positives by choosing the correct size for the bloom filter based on the expected number of entries in it.
In case of saturation, trying to design some strategy to reset the bloom filter or using a scalable bloom filter might be a way to work around it.
Error Rate of Bloom Filters
Being a probabilistic data structure where false positives are possible it is important to know the error rate or the probability of those false positives, the factors they depend upon, and how to minimize them. In this section, we will analyze the probability of false positives in bloom filters by doing a mathematical analysis.
In a bloom filter with 'm' bits, the probability of a string going through a single hash function and then setting a bit to 1 is "1/m". So, the probability of not setting a bit is "1 - 1/m". For 'k' number of hash functions the probability then will be "(1 - 1/m) ^ k". This derived formula is the probability of a single string not setting a bit when passed through 'k' hash functions.
Now for 'n' number of insertions or strings passed the probability will be "(1 - 1/m) ^ (n*k)". But this is not what we are looking for, what we are interested in is the error rate or the probability of us setting the bit by mistake which will be "1 - {(1 - 1/m) ^ (n *k)}". So this whole expression is our probability of setting a 1 by mistake for a single hash function. So again for 'k' hash functions the expression will be "[1 - {(1 - 1/m) ^ (n *k)}] ^ k".
Now, this is the final equation that we were looking for. Let us perform some observations by evaluating some values in the equation.
Assuming m tends to ∞, the value of "(1 - 1/m) ^ (n *k)" will be 1, and the final equation will be "(1-1) ^ k" which is 0, this means that for infinite sized filter the error rate becomes 0 which is not practically possible. Now, let us assume m=1 then "(1 - 1/m) ^ (n *k)" becomes 0 and hence the final equation becomes "(1-0) ^ k" which results in 1. So the error rate becomes 1 i.e. 100% which is obvious because we have only one place to store the bits and thus collision will occur on the second instance.
If we put in some arbitrary values of 'm' for a given value of 'k' we will see that the error rate keeps on decreasing till a certain point and after that, it will again start increasing. This means for a particular value of 'k' there is a certain value of 'm' for which the error rate becomes minimum. This is what we call the optimal value of 'k' and it is given by "(m/n)*log2" which is derived by differentiating the error rate probability formula discussed earlier.
Practical Applications of Bloom Filter
Weak password detection -> The idea is that the system can maintain a list of weak passwords in a form of a Bloom Filter. This can be updated whenever a new user enters a password or an existing user updates the password. Whenever a new user comes, the new password is checked in the Bloom Filter and if a potential match is detected then the user is warned.
Caching -> Bloom filters can be used to cache frequently accessed data in a distributed system, allowing for fast retrieval of data without the need to access the underlying data store.
Network routing -> Bloom filters can be used to route network traffic in a distributed system, allowing for efficient routing of data to the appropriate node.
Reduce Disk Lookups -> Apache Cassandra and PostgreSQL use bloom filters to reduce the disk lookups that result in a considerable increase in the performance of a database query operation.
Facebook also uses bloom filters to avoid one-hit wonders and Medium uses it in its recommendation model to avoid showing posts that the user has already seen.
Conclusion
I hope you have enjoyed reading this article and if it helped you in any way do share and leave your feedback.
Thank you for reading and good luck optimizing your database queries using the above-discussed technique