


In this article, we will be going through an overview of what Kubernetes is starting from the definition, components, basic architecture, etc., and later explaining each of them in detail. So let's get started...
What is Kubernetes?
So Kubernetes is an open-source container orchestration system for automating software deployment, scaling, and management which was originally developed by Google. That means Kubernetes helps us to manage applications that are made up of hundreds or maybe thousands of containers and helps us to manage them in different environments like physical machines, virtual machines, or cloud environments.
What problem does it solve?
The migration from monoliths to microservices architecture caused an increase in the usage of container technologies as the containers actually offer the perfect host for small independent applications. This architecture migration also resulted in applications being comprised of hundreds or maybe thousands of containers.
Now managing these loads of containers across multiple environments using scripts and self-made tools can be complex or even impossible. So that specific scenario caused the need for container orchestration tools.
So what Kubernetes does is:-
High Availability
This means the application rarely has any downtime hence almost always accessible to usersHigh Scalability
A well-scaled application loads fast and users have very high response rates which result in high performanceFault Tolerance or Reliability
It means that if the infrastructure has some problems like when an entire node goes down or data is lost the infrastructure has to have some kind of mechanism to reschedule the process or pick up the data and restore it to the latest state so that the application doesn't actually lose any data.Automated horizontal scaling
It means that if a single service is resource-constrained, Kubernetes will detect this and bring up new instances to handle the additional load and all the new nodes will be automatically added to the cluster.
Architecture
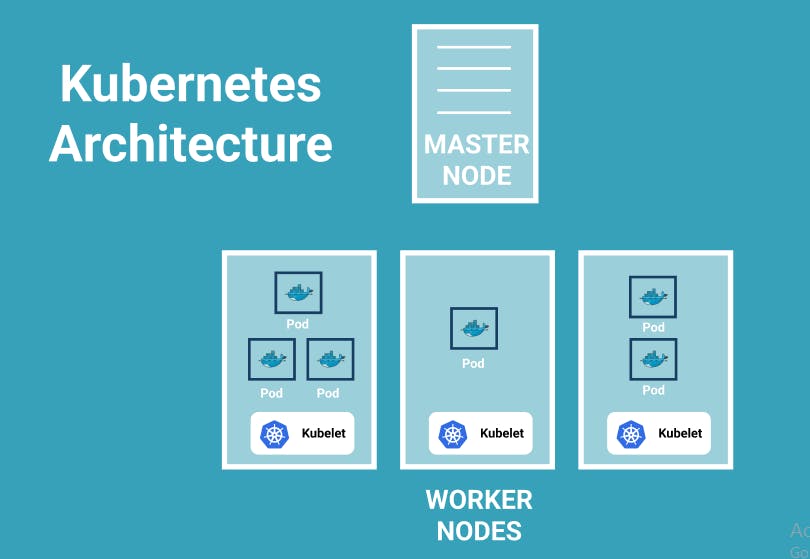
Kubernetes cluster is made up of at least one master node and to it is connected a couple of worker nodes where each node has a kubelet process running on it.
Kubelet is a Kubernetes process that makes it possible for the cluster to communicate with each other and actually execute some tasks on the worker nodes like running application processes.
Each worker node has docker containers of different applications deployed on it so depending on how the workload is distributed you would have a different number of docker containers running on the worker nodes.
The worker nodes are where your application is running and the master node is where several Kubernetes processes that are absolutely necessary to run and manage the cluster properly are running.
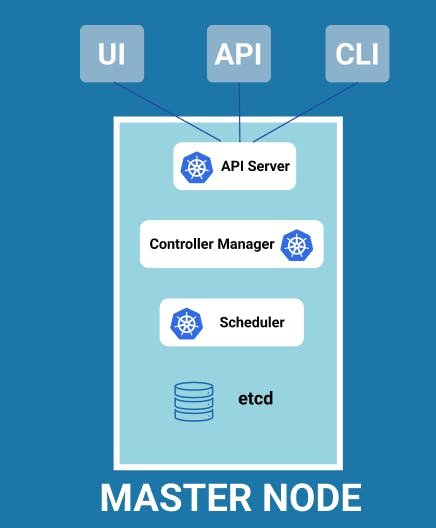
K8s-processes running on Master Node
API Server
It is one of the most important processes running on the master node. It is actually the entry point to the Kubernetes cluster. That means it is the process with which the different Kubernetes clients will talk to like UI if you're using the Kubernetes dashboard, an API if you're using some scripts, and a command-line tool.Controller-Manager
It is another process running on the master node that basically keeps an overview of what's happening in the cluster whether something needs to be repaired or maybe if a container died and it needs to be restartedScheduler
It is another process that is basically responsible for scheduling containers on different nodes based on the workload and the available server resources on each node. So it basically decides on which worker node the next container should be scheduled on, based on the available resources on those worker nodes and the load that the container meets.etcd
Another very important component of the whole cluster is actually an etcd key-value storage which basically holds at any time the current state of the Kubernetes cluster. So it has all the configuration data and all the status data of each node and each container inside of that node. Restoration or Backing up of data is actually made from these etcd snapshots because using that etcd snapshot the whole cluster state can be recovered
Other than these the Kubernetes cluster has another important component called the Virtual Network which in simple words turns all the nodes inside of the cluster into one powerful machine that has the sum of all the resources of individual nodes.
Though the worker nodes have more load the master nodes are still more important as they run very important processes on them and so it is advised to have multiple master nodes in the production environment so that even if one master goes down the application can function properly
Basic Kubernetes Concepts
Now we will go through some of the basic concepts of Kubernetes and how they work
So let's jump in
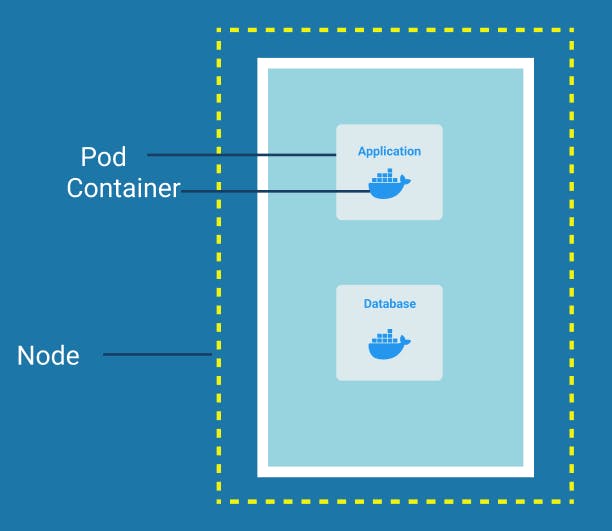
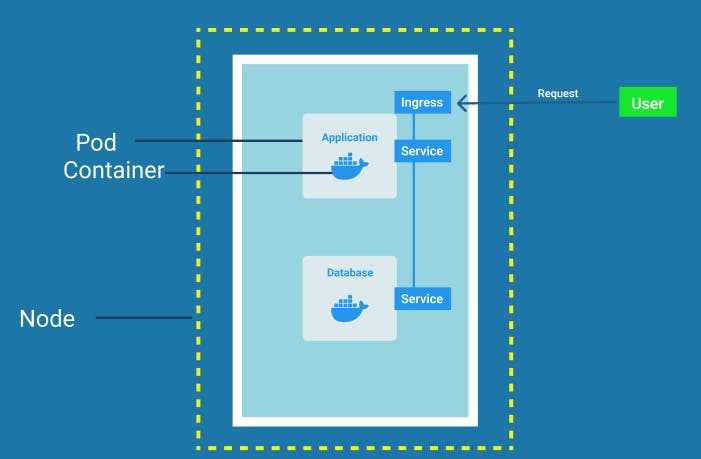
Node and Pods
Node is a simple server, a physical or virtual machine.
A Pod is the smallest unit of Kubernetes that a user can configure or interact with. It acts as a wrapper of a container and on each worker node we can have multiple pods and inside of a pod, there can be multiple containers.
Usually, it is one pod per application unless there is a need for more than one container inside of a pod, for example when you have the main application that needs some helper containers
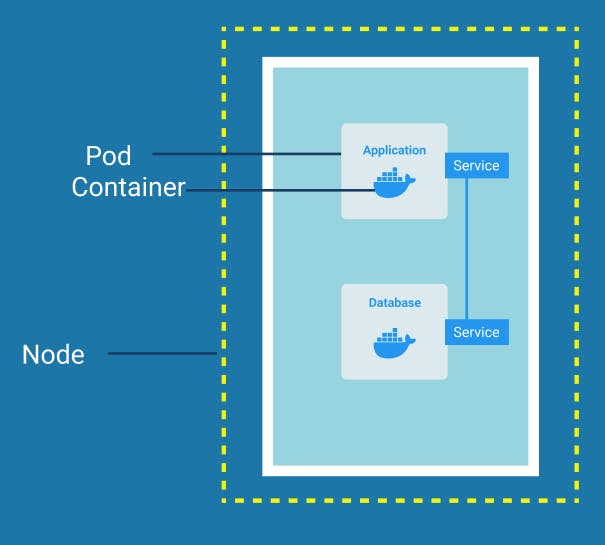
Service
As we previously discussed there is a Virtual Network that manages the Kubernetes cluster. So it assigns each pod its own IP address and so each pod is in its own self-containing server with its own IP address. Each Pod can communicate with each other using that internal IP addresses.
Now Pods can die very frequently and when a pod dies a new one gets created. Whenever a pod gets restarted or a new pod is created it gets a new IP address.
So for example, if you have an application talking to a database pod using the IP address the pods have and the pod restarts, it gets a new IP address and thus it won't be able to communicate with the database pod anymore using the old IP address. Hence, it is difficult to keep managing this change in IP addresses.
To solve this problem Service is used which basically is an alternative or a substitute to these dynamic IP addresses. In simple words, we can think of Service as a static IP address that can be attached to each Pod. The life cycles of Service is not connected to that of the Pods which is why when a pod dies and a new pod is created in its place, it still has the same Service. Thus to communicate with that Pod the endpoint doesn't need to be changed anymore.
So even when a pod dies and gets restarted the other pods would still communicate with it through the same service sitting in front of it.
Ingress
We want our application to be accessible through a browser and for this, an external Service would be needed.
An external Service is a service that opens the communication from external sources and this type of service is only created for the application we want to be accessed publicly. For example, an external Service won't be created for a Database Pod as we don't want our database to have external access.
Now, the URL of the external Service of our application would look like http://my-app-service-ip:port, that is it is made up of an HTTP protocol followed by a node IP address and port number of the service. This is good for developers to test the application locally but not for the clients to access the end product.
So we need Ingress, which manages external access to the services in a cluster. So the client-side request instead of Service first goes to the Ingress and then gets forwarded to the Service. In simple words, we can say it gives Services externally-reachable URLs like https://my-app.com as well as provides load balancing, SSL termination, and name-based virtual hosting.
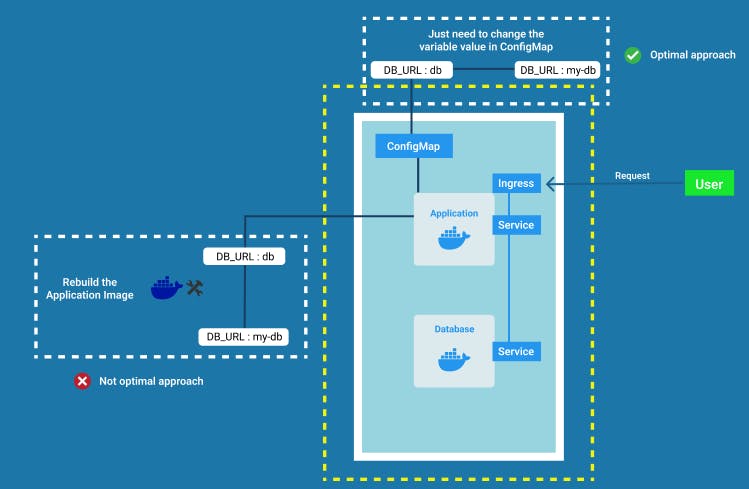
ConfigMap
Pods communicate with each other using a Service. Let's assume if the Service name of the database Pod changes by any means, then our application won't be able to communicate with it anymore. So we have to adjust it in the built image of the application where most of our configurations would be. But to adjust this small change in the Service endpoint we have to rebuild the application > push it to repository > pull that new image in our pod which is a lot of work for a small change.
To sort this issue Kubernetes has a component called ConfigMap. It basically would contain non-confidential configuration data in key-value pairs, for example, database URLs or even other Services, and instead of rebuilding and redeploying the application all we have to do is just adjust the value in ConfigMap and restart the application pod which will save us a lot of time.
It is then connected to the Pod which consumes the data that the config map contains as environment variables, command-line arguments, or as configuration files in a volume.
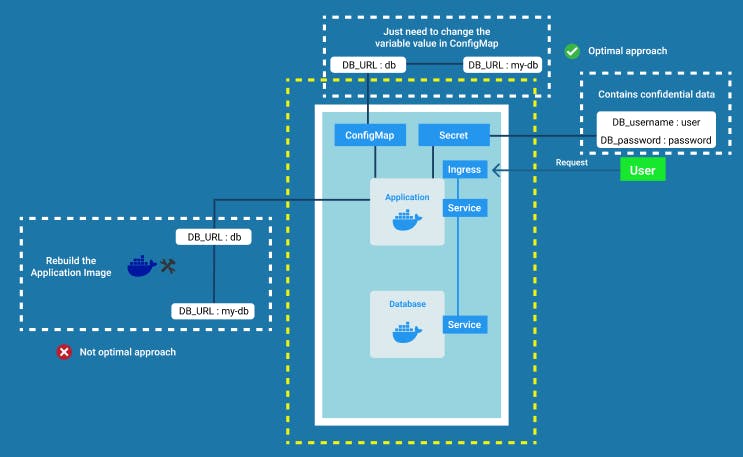
Secret
ConfigMap does not provide secrecy or encryption. Suppose along with the Database URL, the username and password are also being changed. But keeping these sensitive data in a ConfigMap would be insecure although it is an external configuration.
To store these kinds of confidential data we use a Kubernetes component called Secret. In Secret, the data is stored in base64 encoded format. So basically it is like ConfigMap but contains data that other people won't have access to.
Volumes
We already know that pods die frequently and when a pod having some data dies all the data inside it would also be gone. For example, if we have a database Pod having all of our records in it and if it dies and is restarted then all our records would be lost. So this is a huge problem as most of the time we want reliable persistence of data.
Volumes solve this problem by attaching physical storage on a hard drive to the Pod.
That storage could either be on a local machine meaning on the same server node where the pod is running or it could be on remote storage meaning cloud storage which is not part of the Kubernetes cluster and can be accessed through an external reference. So even when the pod dies and is restarted the data is not lost as it is being persisted.
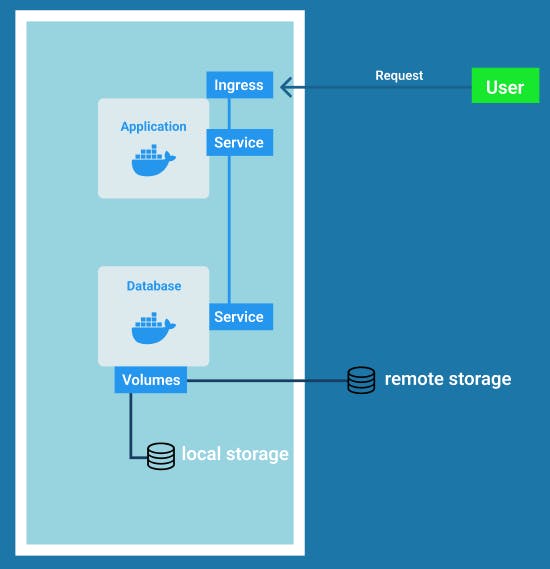
Kubernetes cluster does not manage any data persistence on its own. So a user or an administrator is responsible for the backing up and replication of data along with managing and storing it on hardware.
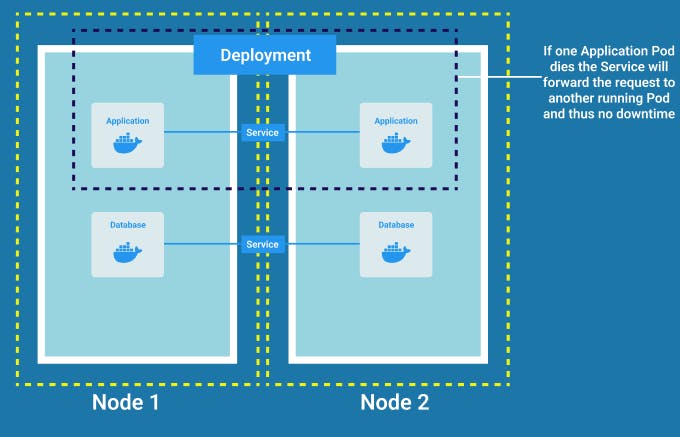
Deployement
Suppose our application pod dies and is being restarted which will take some time. That means the users that are able to access the application through a browser will face some downtime which is a very serious issue.
Here we can take up the advantage of distributed systems and containers. So instead of relying on just one application pod and one database pod, we can replicate everything on multiple servers so we would have another node where a clone of our application would run which will also be connected to the same Service. Service will also act as a load balancer and will forward the request to the part having less traffic. But in order to create the replica of the application pod, we would define a blueprint of the application pod, mostly in the form of a YAML file, and then specify how many replicas of that pod we need to run. This blueprint is called a Deployment.
Basically, Deployment acts as an abstraction layer on top of pods which makes it easier to interact with and scale them.
In practice we work with Deployments instead of working with Pods So now if one of the application pods dies the request would be forwarded by the Service to any of the other replicas.
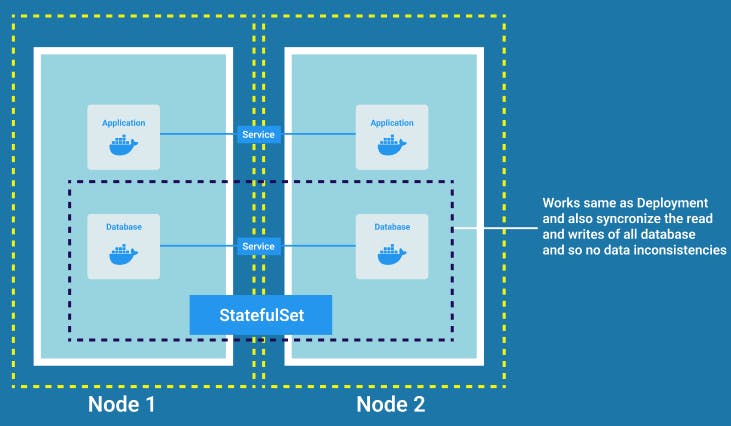
StatefulSet
Now if our database pod also dies we would need a replica of it. But we cannot replicate a database using deployment and the reason for that is because the database has a state that is the data it holds. This means that if we have replicas of the database then their read and writes should be synchronized which is not the case for Deployments and eventually it gives rise to data inconsistency which is highly undesirable.
Thus another Kubernetes component StatefulSet is used which along with performing the replication and scaling of pods also helps to synchronize the database replica pods so that no data inconsistency can take place.
StatefulSet is meant specifically for applications like databases or other stateful applications, for example, MongoDB, MySQL, ElasticSearch, etc.
Deploying database applications using StatefulSet in the Kubernetes cluster is kind of difficult because of certain limitations like the requirement of a persistent volume provisioner and many more.
So it is a common practice to host database applications outside of the Kubernetes cluster and just have the deployments or stateless applications that replicate and scale inside of the Kubernetes cluster communicating with the external database
I hope you learned something new from reading the blog.
Do leave your feedback and have a great day.
Thank You!!